

This blog post is for you, <u>Python</u> lovers. Last year there was an experiment conducted.
Data science students were asked to improve their code snippets for data preprocessing. Some parts of the snippets were sub-optimal, and other parts were, well, thought to be optimal. Let’s take a look at what came as a result of this experiment. A piece of advice: while reading, don’t just skim through the text. Instead, try to guess which of the proposed code options are the fastest.
Task number 1 - eliminate the dollar sign
Let's say we have a Pandas data-frame, in which one of the columns is a string that contains price with the dollar sign at the end (fig 1). We need to convert it to an integer, i.e. remove the dollar sign and convert this type to int (price($)_v1).
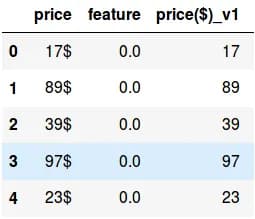
fig. 1
The following solutions are possible:

fig. 2
The first option was offered to the students as a basic one. The logic here is simple: the outermost character is split off and is converted to int type. There is an obvious suboptimality here: you cannot translate it into the new type "element by element". The second option fixes this suboptimality. The disadvantage of both options is that they work only if the dollar sign is valid at the end of each string value of the attribute. The third option is more universal, which removes the dollar sign with help of the replace function. And in the fourth option, the lambda function is excluded. The execution time is shown on a bar chart (hereinafter, the time is calculated for a data frame with the number of rows = 10,000,000):
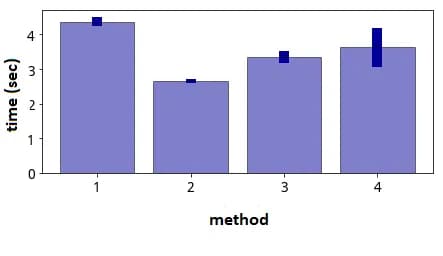
fig. 3
It has to be mentioned that the students did not choose the time-optimal option, they relied on the replace function. The fourth option, in theory, is an improved third option, though there’s a curveball: on average, it is slower than its progenitor. For some reason, lambda functions here are faster than the .str interface.
Task 2 - binarize the column
The statement here is quite simple: in the Pandas data frame, there is a string attribute of two values: A and B. The task is to turn it into a binary attribute (in fig. 4 the type attribute is correctly converted to type_v1).
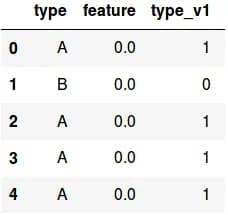
fig. 4
There is a bunch of solutions here:

fig. 5
The first method uses a lambda function (there is a deliberate mistake with early typecasting - please refer to the previous task), the second is an ordinary comparison, the third is a convenient np.where function, the fourth is a universal encoding using a dictionary (this is the preferred option), and the next three methods use special data preprocessing functions from different libraries. Note that two of them can give an incorrect answer as they do not receive the desired feature, but the inversion to it. It's easy to fix, so let’s not concentrate on that. In addition, the first three methods are applicable only for binarization, while the others are easily generalized to a larger number of categories.
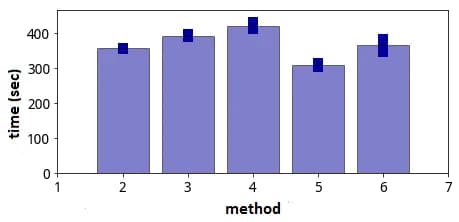
fig. 6
Now let's take a look at the binarization time (fig. 6 above). For the first and the last method the binarization time is not presented, since it is significantly inferior to others. LabelEncoder from scikit-learn library turned out to be very slow (at least for the purpose of this task). The fastest way is through factorize (pop quiz: will the invalidation make it slower?). Now, if you want to binarize in a simple way, you should compare the value with the desired one (second method).
Task 3 - split the column
In the string column of a Pandas data frame, the values are put in an "A/B" form. The task is to split this column into two: the A parts should be in the first column and B parts in the second. In fig. 7 below, column A/B splits correctly into A_v1 and B_v1.
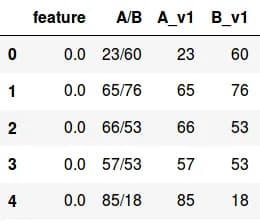
fig. 7
Let's consider several ways to solve this problem:

fig. 8
It was astonishing to see that the first way was not the fastest one. The next two ways try to implement the first one "in one line", which is through coercion to lists or through coercion to a data-frame. The second approach is faster than the first, while the third is expected to be very time-consuming (since it receives a data frame and then uses it to insert values into the original data frame). The last method is very original and was suggested by a student. It is highly sensitive to incorrectness in the format, but, as it turned out, is very fast. You just need to transfer to the NumPy matrix.
Task 4 - replace the gaps with the middle value
There is a Pandas data frame, which has a “type” service attribute - its values "train" and "test" mark the training and the control parts of the sample. There is also a “feature” attribute that has quite a few gaps. The task requires all the blanks to be filled in. Moreover, in the rows that correspond to training, the task is to fill in the average value of the attribute for training, and, similarly, in the control objects the task is to fill in the average for control (fig. 10; in feature_v1 there is an example of correct filling).
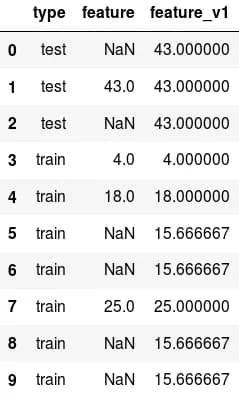
fig. 10
Let’s take a look at several solutions:
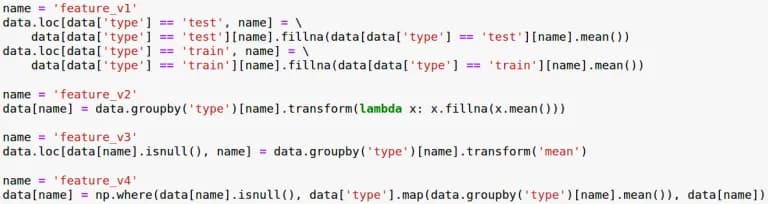
fig. 11
The first solution is simple but very cumbersome and difficult to understand. The second and third are written through the magic-like transform function. The last one was come up with when trying to rewrite everything using the np.where function.
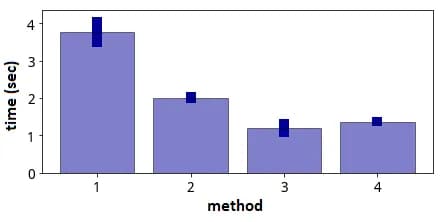
fig. 12
The least time-consuming method was number three, which, however, seems to be a little weird and at the first glance it was assumed that there would be an error. Notably, this method could have been accelerated in the previous Pandas versions and is no longer possible to do so in the newest one. The last method, which the author performed himself is also pretty good and the code seems to be understandable.
The coding examples in this post can be found on the author's github. The best way to view everything is this way (the github viewer shows things incorrectly). When preparing the publication, we used code fragments from Gleb Maslyakov and Denis Bibik.