

We’ll talk about two things - a deep learning approach that solves the problem of reducing the sample size and an even more ambitious task - creating synthetic data that stores all the useful information about the sample. In this post you'll be learning to distill, so to speak.
History and terminology of data distillation
DD is a significant reduction of the sample that happens by creating artificial objects (synthetic data) that aggregate useful information stored in the data and allow tuning machine learning algorithms no less efficiently than on all data to distill deep learning.
Initially, the term "distillation" appeared in Hinton's work [1], then the "knowledge distillation” term was established and is now widely recognized. Knowledge distillation means the construction of a simple model based on complex/several models. It was introduced to distill neural network information.
Even though the terms sound similar, it is a completely different topic that solves a different problem.
There are many classic methods for selecting objects (Instance Selection), ranging from the selection of so-called etalons in metric algorithms to the selection of support vectors in support vector machines (SVM). But distillation is not a selection, but a synthesis of objects (it’s similar to the difference between the feature selection and dimensionality reduction, only in this particular case we are not talking about features, but about objects). In the era of deep learning, it became possible to create synthetic data using a uniform optimization technique - by synthesizing objects (instead of sorting through one object after another).
In short, the distillation of data is a technique used to reduce the size of the training dataset and improve model accuracy. The idea behind using a smaller training dataset is to learn the model faster, as the model is not required to learn the entire dataset. This is done by learning the model using only a subset of the data, and then when the model is deployed, the learned model from the subset of the data can be used to produce the same accuracy, as the model learned from the full dataset. By doing so, the model learned from a smaller set of data is more portable and can be deployed easily to many different datasets. In this case, a smaller training dataset is used to train a more accurate model on a larger training dataset.
The basic idea is to use the training data to learn how to learn, instead of needing to use the entire training dataset to train the model. This is because of the fact that not all of the data is relevant to all of the examples, thus removing irrelevant data will make training easier. In fact, in some cases, removing some of the irrelevant data can improve model accuracy. So, data distillation is the process of removing unnecessary data to make training easier.
We will talk about some of the research papers on this topic below. Note that data distillation machine learning is needed for:
-
acceleration of training/testing (preferably for a whole class of models),
-
reducing the amount of data for storage (replacing the classic Instance Selection),
-
answering a scientific question: how much information is contained in the data (how much we can “compress” it).
Distillation method
The idea of deep learning distillation of data was proposed in the research paper [2], in which an MNIST dataset of 60,000 images was reduced to 10, ie. in synthetic learning there was one representative image for each class! At the same time, the LeNet was trained on synthetic data to approximately the same quality as for the entire sample (though much faster) and converged in several steps. However, training a differently provisioned network was already degrading the quality of the solution. Fig. 1 that came from the research paper [2] shows the main result and the obtained synthetic data in the MNIST and CIFAR10 problems and it’s notable that for the MNIST dataset the data is not at all similar to real numbers, although it is logical to expect that a synthetic representative of class "zero" is something similar to zero, see also fig. 2.
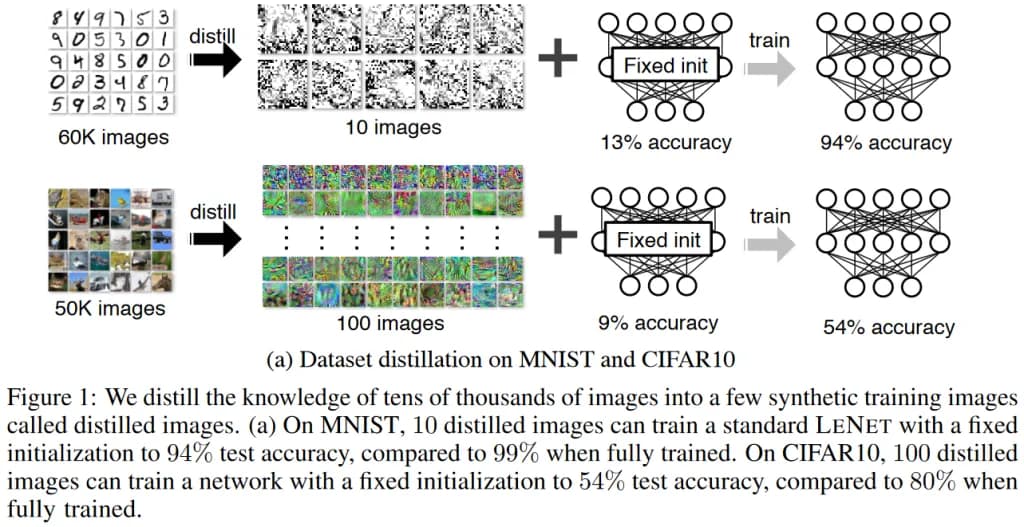
fig. 1 from [2]

fig. 2 from [2]
The basic idea of the method proposed in [2] is that we want the synthetic data to be such that when using gradient descent on them we get to the minimum of the error function, ie. it is necessary to solve the following optimization problem:
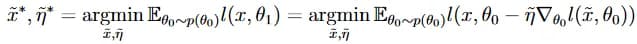
*fig. 3 *
θt here is the vector of network parameters at the t-th iteration, at zero iteration they are taken from the distribution p(•), x with a “wave" is synthetic data, x (without a “wave”) is a training sample, l(x, θ) is a neural network error function for the entire training set. Note that the formula uses only one step of the gradient adjustment of the original neural network, we will generalize this further in a bit. The main problem that arises here is if the proposed optimization problem is solved by the gradient method, then we must take the gradient from the gradient
In a more general sense we stop hoping to fall into at least one gradient descent step and use multiple steps instead. Moreover, it is possible to specify several sets of parameters from the distribution p(.) Thus, synthetic data will be suitable for several neural networks with different parameters. The algorithm for searching synthetic data in general is shown in fig. 4. This generalization allows obtaining synthetic data that is more similar to the original data.


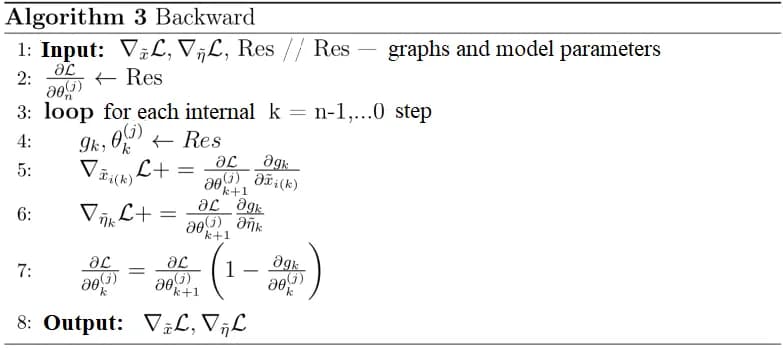

fig. 4
Method development
The research paper [2] gave impetus to a new direction of research. Research paper [3], for instance, showed how to improve data compression during distillation, using "fuzzy (soft) labeled" data, so in the MNIST problem a representative of the artificial data could belong to several classes at once with different probabilities. Not only the data was distilled, but also were the labels. As a result, learning on a sample of only 5 distilled images, you can get an accuracy of about 92% (this is, however, worse than 96% obtained in the previous paper). It goes without saying that the more synthetic data, the better its quality (fig. 6). Moreover, in paper [3], distillation was used for texts (albeit a little artificially, i.e. by cutting off or complementing the texts to a fixed length).

fig. 5
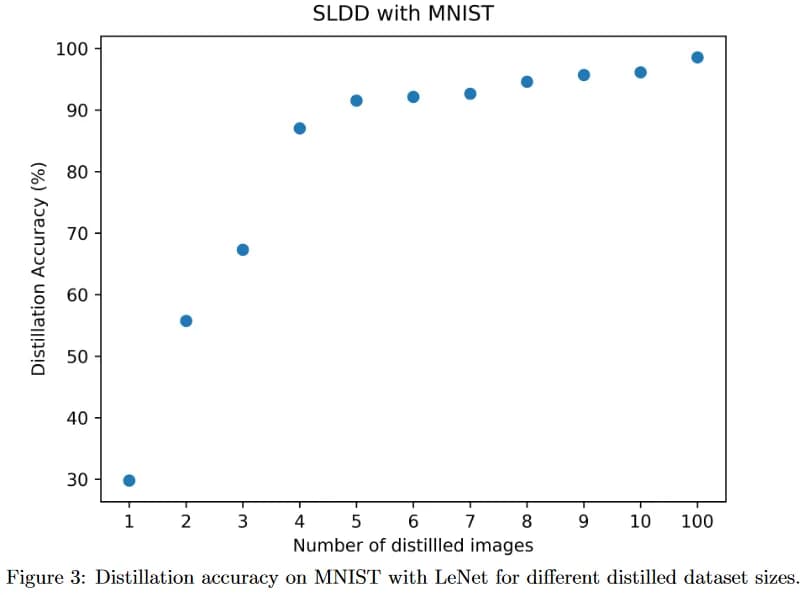
fig. 6
Author's experiments in distillation
When the author found the research paper [2], it seemed that it was greatly underestimated. Though it has practical importance close to zero,
-
a "regular" and very logical method of data aggregation, tailored "for the model" was proposed,
-
many problems were introduced (e.g. obtaining synthetic data similar to the original),
-
it was interesting to see how it all works for tabular data,
-
there was a purely engineering challenge to create a "more efficient synthesis" of artificial data.
Dmitry Medvedev, a Moscow State University Masters student, became interested in DD and conducted several experiments. Dmitry and I haven’t yet completed the other experiments because the described two-level optimization is performed very slowly, and because we don’t have Google's processing power. That being said, we decided to see how the method works for tabular data. Below are images that stand for the classic "two moons training dataset'' model problem as well as for several simple neural networks: one-layer, 2-layer, and 4-layer. Note that even for such a simple task and simple models, the total distillation time reached 4 hours.
We investigated how the test quality depended on the number of epochs when solving the minimization problem for constructing synthetic data (note: these are not epochs of learning neural networks), the number of steps in the same task, the number of neural networks for which data is synthesized (the number of initial parameters) (fig. 7).
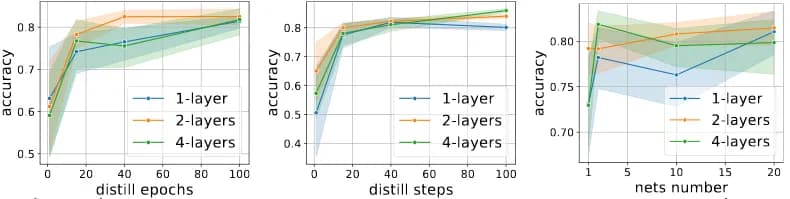
fig. 7
(from left to right) test quality for the number of epochs, the number of steps, and the number of distillation networks)
Fig. 8 shows a synthetic sample obtained at different steps of the method for different architectures. The problems that arose for data of a different nature remain: synthetic objects don’t look like sample objects. We are yet to find a solution to this problem.
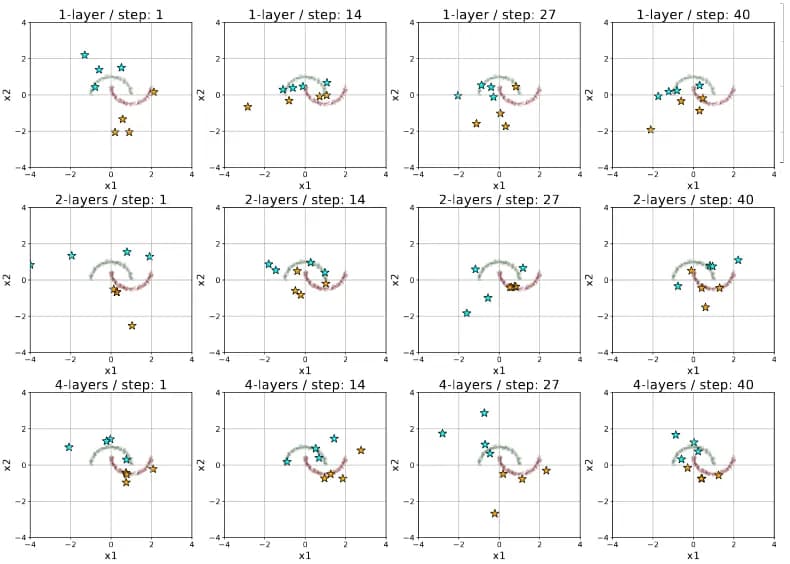
fig. 8
Fig. 9 shows how models that are tuned on synthetic data work.
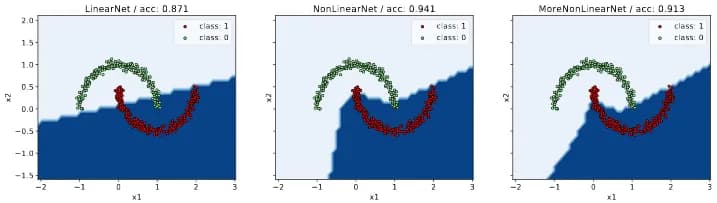
fig. 9
Separating surfaces of networks of varying complexity, trained on distilled data
We also looked at how synthetic data built for one architecture is suitable for other neural network architectures (fig. 10) and proposed a method for distilling data for several architectures at once. We also managed to demonstrate the effect that a network trained on distilled data can be better in quality than a network trained on the entire sample.
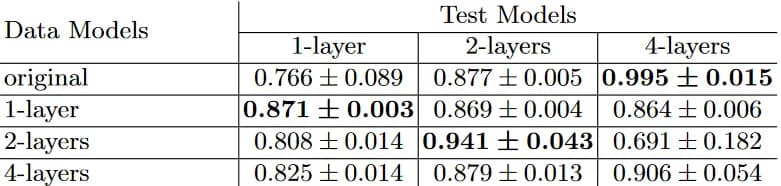
fig. 10
The quality of models based on different data: from original to distilled ones that are made for a specific architecture
Our research on distillation continues. For now the research paper [4] is ready and its edited version was presented at a recent conference AIST-2020. The code [5] was also posted. In the meantime, several more research groups are doing similar work.
References
[1] Hinton, G., Vinyals, O., Dean, J.: Distilling the Knowledge in a Neural Network // NIPS (2015)
[2] Wang, T., Zhu, J., Torralba, A. and Efros, A. Dataset Distillation, 2018.
[3] Sucholutsky, I., Schonlau M. «Soft-Label Dataset Distillation and Text Dataset Distillation»
[4] Medvedev D., D’yakonov А. «New Properties of the Data Distillation MethodWhen Working With Tabular Data», 2020.
[5] https://github.com/dm-medvedev/dataset-distillation
Extra:
Hao-Ting Li, Shih-Chieh Lin, Cheng-Yeh Chen, Chen-Kuo Chiang. “Layer-Level Knowledge Distillation for Deep Neural Network Learning (distillation deep learning/distill. deep learning”, 2019