

Let’s say you have a working and a developer-friendly .NET ecosystem. There are a lot of services and your team doesn’t cherish the idea of having a service built without .NET. Additionally, there is a pending request to develop software to serve some machine learning models.
Most of the machine learning models are created with Python and libraries like scikit-learn, PyTorch, or TensorFlow. Here come the questions. Should the team just implement a Python service with the abovementioned libraries? Perhaps using ML.NET for the sake of the ecosystem consistency would be a better solution? I will try to find some rationale behind these solutions. To resolve it I made inferences of the ResNet18 deep learning model using PyTorch and ML.NET and compared their performance.
PyTorch Performance
PyTorch is a widely known open source library for deep learning. The framework aims to hasten the path from research prototyping to production deployment. Some of its key features include:
Production-ready deployment options: While PyTorch is a relatively new framework, it now boasts of an ML model serving framework, TorchServe, which developers can use to deploy PyTorch models.
Distributed training applications: PyTorch offers different means for distributing training workloads across micro-processers with torch.distributed that features three main components, Distributed Data-Parrel Training, RPC-Based Training, and Collective Communication.
Expanded Capabilities & Ecosystem: PyTorch’s robust ecosystem makes it adaptable for many problems in computer vision, NLP, sequence prediction, and more.
It’s no wonder that most of the researchers use it to create a state of the art models. It’s a popular choice for Python developers to evaluate acquired models.
PyTorch inference testing & results
To get measurements of the models I used the following environment and hardware:
GeForce GTX 1660.
AMD Ryzen 5 3600.
Ubuntu 18.04.
CUDA Toolkit 10.1.
cuDNN 7.0.
torch 1.7.1.
torchvision 0.8.2.
The ResNet18 model is obtained from the PyTorch Hub. In order to get the inference times, I made 10000 inferences with GPU and CPU. At this point my interest didn’t lie in the output of the model so using a random tensor as an input sufficed. It’s also the reason why I didn’t scale the input tensor. I used this code to generate inference time:
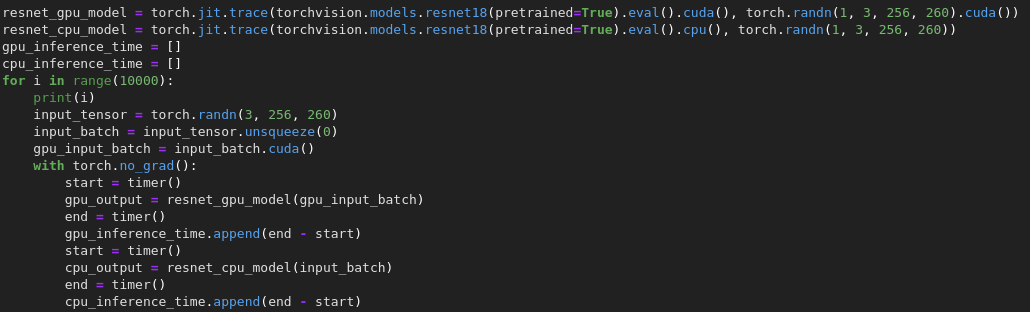
The following distributions were received after the code execution:

The mean inference time for CPU was `0.026` seconds and `0.001` seconds for GPU. Their standard deviations were `0.003` and `0.0001` respectively. GPU execution was roughly 10 times faster, which is what was expected. Now, performance tuning methods are available to make PyTorch model inference fast. They include best practices such as enabling augmentation and asynchronous data loading. At the same time, you can disable gradient calculation and bias for convolutions. More best practices can be found here.
Multiple models may run on the same CPU concurrently by utilizing the PyTorch multiprocessing inference feature, which may be useful in various scenarios. You can explore more on the issue of CPU threading and Torchscript inference.
Review of ML.NET: Introduction
ML.NET is a machine learning framework built for .NET developers, allowing them to leverage their existing skills to easily add ML capabilities to their apps without a lot of prior knowledge of ML.
There are several ML NET benefits. It has a built-in AutoML allowing you to avoid choosing the best type of model manually. Initially, it lacked the possibility to define and train your own neural networks. But the ML NET model builder now comes with a series of tools that make it possible to build, train, and deploy custom ML solutions from visual studio. The team is still working towards a stable release as the current version supports limited file formats. Another advantage is that everything is available to run the models locally with no requirement to connect to the cloud. The ml.net model builder remains free for all uses along with ML.NET. But if you’re considering an alternative to ML builder, you can import your model in ONNX format from PyTorch with the following code:
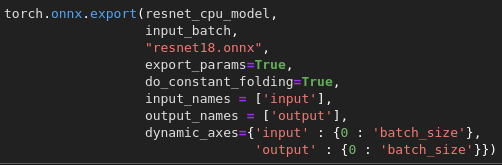
ML.NET heavily relies on the ONNX Runtime accelerator to make use of the deep learning models and all the inferences are made using ONNX Runtime.
For additional user-case scenarios, developers can easily integrate ML libraries such as TensorFlow, ONNX, and Infer.NET for additional scenarios. The technology is proven and already backs popular Microsoft solutions like Outlook, Bing, PowerBI, and Microsoft Defender.
ML.NET inferences: Testing and Results
To conduct ML.NET inferences I used the same hardware but another environment because of ML.NET requirements:
Ubuntu 18.04.
CUDA Toolkit 10.2.
cuDNN 8.
This ML.NET code will have a more thorough description because it’s much less popular than PyTorch. At the first step, we need to install NuGET packages with ML.NET and ONNX Runtime:
Microsoft.ML 1.5.4.
Microsoft.ML.OnnxRuntime.Gpu 1.6.0.
Microsoft.ML.OnnxTransformer 1.5.4.
Before trying to make any inference we need to create two classes representing the input and output of the model:
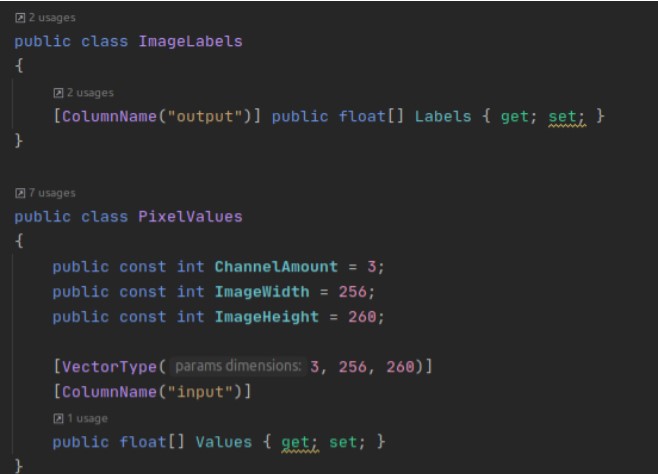
The most important thing is to create `MLContext` object. This object is central to the ML.NET framework. Every inference and preprocessing operations are defined with it. It has a nice feature to set a random seed to make operations deterministic.
As the next step, you can define a model estimator, fit it to let it know about the input data scheme, and finally create a prediction engine. This can be achieved with the following code:
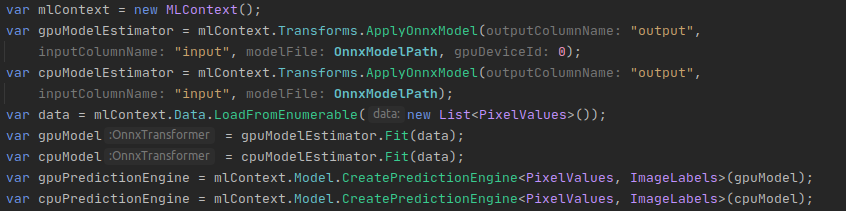
Finally, you can create some input data, make inferences, and look at your estimation:

This resulted in the following distributions:

Mean inference time for CPU was `0.016` seconds and `0.005` seconds for GPU with standard deviations `0.0029` and `0.0007` respectively.
Conclusion
Upon measuring the performance of each framework we can summarize it with the following graph:
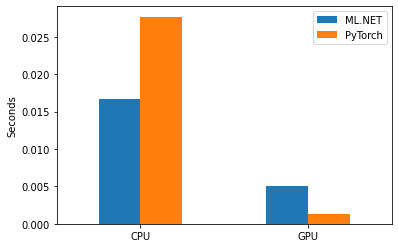
ML.NET can evaluate deep learning models with a decent speed and is faster than PyTorch using CPU. It can be a dealbreaker for production use. With ML.NET you can have all the advantages of the .NET ecosystem, fast web servers like Kestrel, and easily-maintainable object-oriented code.
Yet there are some drawbacks to take note of. PyTorch GPU inference is faster. Using ML.NET for some tasks which rely heavily on GPU computation may be slower. Before evaluating a model you would often need to preprocess your data. Even though ML.NET has a rich library of different transformers for data preprocessing, it may be a complex task to reproduce the same preprocessing in your .NET software.
Deciding what framework to use depends on your current situation. How much time do you have to develop the service? How important performance is for you? Does data preprocessing depend on some Python library? You need the answer to all of these questions while keeping in mind ML.NET and PyTorch framework performance.