

The logistic loss or cross-entropy loss (or simply cross entropy) is often used in classification problems. Let's figure out why it is used and what meaning it has. To fully understand this post, you need a good ML and math background, yet I would still recommend ML beginners to read it (even though the material in this post wasn’t written in a step-by-step format).
Let's start from afar…
What is log? A logarithm is the number indicating the power to which another number must be raised to get a given third number.
What is loss I will not define, as if you are reading this it is obvious to you.
What is Log Loss?
Now, what is log loss? Logarithmic loss indicates how close a prediction probability comes to the actual/corresponding true value.
Here is the log loss formula:

Let's think of how the linear regression problem is solved. We want to get a linear log loss function (i.e. weights w) that approximates the target value up to error:
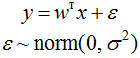
We assumed that the error is normally distributed, x is the feature description of the object (it may also contain a fictitious constant feature so that the linear function has a bias term). Then we know how the responses of our function are distributed and we can write the likelihood function for log likelihood interpretation of the sample (i.e., the product of the densities into which the values from the training sample are substituted) and use the maximum likelihood estimation method (in which the maximum likelihood is taken to determine the values of the parameters, and more often its logarithm):
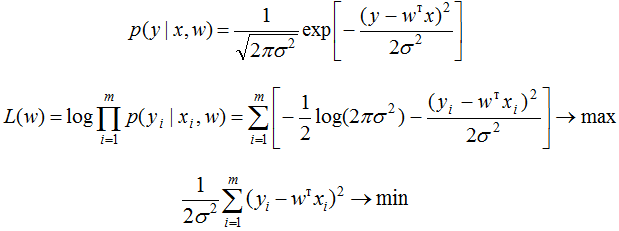
As a result, it turns out that maximizing the likelihood is equivalent to minimizing the mean square error (MSE), i.e. this error function is widely used in regression problems for a reason. In addition to being quite logical, easily differentiable by parameters and easily minimized, it is also theoretically substantiated using the maximum likelihood estimation method if the linear model matches the data accurate to normal noise.
Let's also see how the stochastic gradient (SGD) method is implemented to minimize MSE: we need to take the derivative of the error function for a specific object and write the weight correction formula in the form of a "step towards the antigradient":
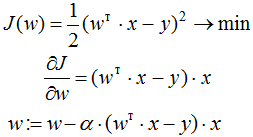
We found that the weights of the linear model, when trained by the SGD method, are corrected by adding a feature vector. The coefficient with which they are added depends on the "aggressiveness of the algorithm" (the alpha parameter, which is called the learning rate) and the difference "the algorithm's answer is the correct answer." By the way, if the difference is zero (that is, the algorithm gives an exact answer for a given object), then the weights are not corrected.
Log loss
Now let's finally talk about our topic. We consider the classification problem with two classes: 0 and 1. The training set can be considered as an implementation of the generalized Bernoulli scheme: for each object, a random variable is generated, which with probability p (its own for each object) takes the value 1 and with probability (1–p) - 0. Suppose that we are building our model so that it generates the correct probabilities, but then we can write the likelihood function:

After taking the logarithm of the likelihood function, we found that maximizing it is equivalent to minimizing the last recorded expression. This is what is called the "logistic error function". For a binary classification problem, in which the algorithm must output the probability of belonging to class 1, it is logical just as much as the MSE is logical in a linear regression problem with normal noise (since both error functions are derived from the maximum likelihood estimation method). By the way what is log likelihood? It is the way to measure how fit a model is for a dataset. It is the way to measure how fit a model is for a dataset. For a binary classification problem, in which the algorithm must output the probability of belonging to class 1, it is logical just as much as the MSE is logical in a linear regression problem with normal noise (since both error functions are derived from the maximum likelihood estimation method).
It is often much more understandable to record an error on a single object like this:
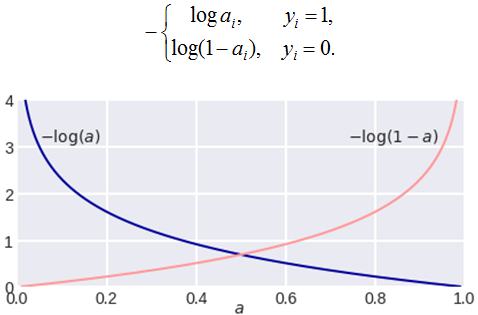
Note the unpleasant property: if for an object of the 1st class we predict a zero probability of belonging to this class or, conversely, for an object of the 0th we predict a unit probability of belonging to class 1, then the error is equal to infinity! Thus, a blunder on one object immediately renders the algorithm useless. In practice, it's is often limited to some large number (so as not to mess with infinities).
If we ask ourselves which constant algorithm is optimal for a sample of q_1 representatives of class 1 and q_0 representatives of class 0, q_1+q_0 = q, then we get the following:
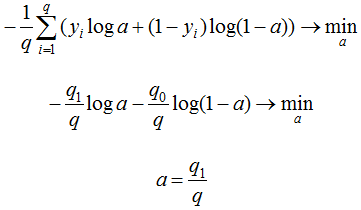
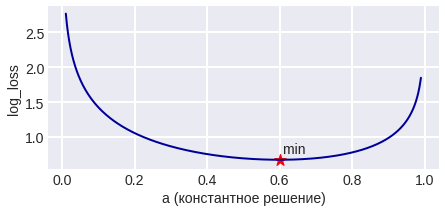
The last answer is obtained by taking the derivative and equating it to zero. The described problem has to be solved, for example, when constructing decision trees (what label to assign to a leaf if representatives of different classes are included in it). The figure below shows a graph of errors of the constant algorithm for a sample of four objects of class 0 and 6 objects of class 1.
Now imagine that we know that the object belongs to class 1 with probability p, let's see which answer is optimal on this object from the point of view of log_loss: the expected value of our error is as follows:
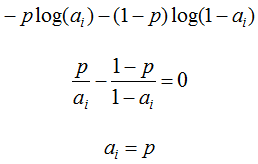
To minimize the error, we again took the derivative and equated it to zero. We learned that it is optimal for each object to give its probability of belonging to class 1! Thus, to minimize log_loss, one must be able to calculate (estimate) the probabilities of belonging to classes.
If we substitute the obtained optimal solution into the functional to be minimized, then we get the entropy:
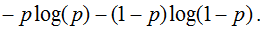
This explains why the entropy criterion of splitting (branching) is used when constructing decision trees in classification problems (as well as random forests and trees in boosting). The fact is that the assessment of belonging to class 1 is often made using the arithmetic mean of marks in the leaf. In any case, for a particular tree, this probability will be the same for all objects in the leaf, i.e. constant. Thus, the entropy in the leaf is approximately equal to the error of the constant solution. Using the entropy test we are implicitly optimizing the logloss!
To what extent can it vary? It is clear that the minimum value is 0, the maximum is +∞, but the effective maximum can be considered an error when using a constant algorithm (we can hardly come up with an algorithm worse than a constant in solving the problem), i.e.
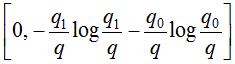
It is notable that if we take a logarithm with a base of 2, then on a balanced sample it is the segment [0,1].
Connection with loss function in logistic regression
The word "logistic" in the name of the error hints at a connection with loss function in logistic regression - this is just a method for solving the problem of binary classification, which gets the probability of belonging to class 1. But so far we have been proceeding from the general assumptions that our algorithm generates this probability (the algorithm can be, for example, a random forest or boosting over trees). Let's see that there is still a close connection with loss function in logistic regression… let's see how the logistic regression (i.e. sigmoid from a linear combination) is adjusted to this error function by the SGD method.
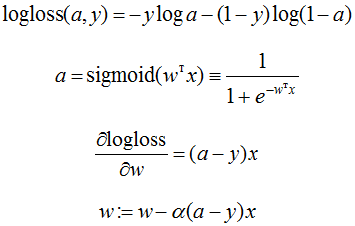
As we can see, adjusting the weights is exactly the same as when adjusting linear regression! In fact, this indicates the relationship of different regressions: linear and logistic, or rather, the relationship of distributions: normal and Bernoulli.
In many books, another expression goes by the name of log loss function (that is, precisely "logistic loss"), which we can get by substituting the expression for the sigmoid in it and redesignating: we assume that the class labels are now -1 and +1, then we get the following:
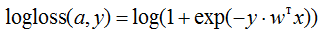
It is useful to look at the graph of the function central to this view:
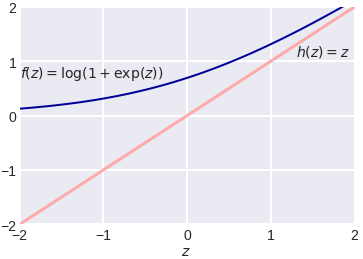
As you can see, this is a smoothed (differentiable everywhere) analog of the max (0,x) function, which in deep learning is commonly called ReLU (Rectified Linear Unit). If, when setting the weights, we minimize it, then in this way we set up the classic log loss logistic regression, but if we use ReLU, slightly correct the argument and add regularization, then we get the classic SVM setting:
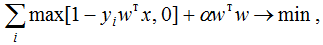
the expression under the sum sign is usually called Hinge loss. As you can see, often seemingly completely different methods can be obtained by "slightly correcting" the optimized functions to resemble similar ones. By the way, when training RVM (Relevance vector machine), very similar functionality is also used:
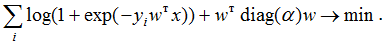
Relationship with the Kullback-Leibler divergence
Kullback-Leibler divergence is often used (especially in machine learning, Bayesian approach, and information theory) to calculate the dissimilarity of two distributions. It is determined by the following formula:
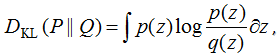
P and Q are distributions (the first is usually "true", and the second is the one about which we are interested in how much it looks like true), p and q are the densities of these distributions. The KL divergence is often referred to as distance, although it is not symmetric and does not satisfy the triangle inequality. For discrete distributions, the formula is written as follows:
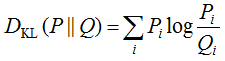
P_i, Q_i are the probabilities of discrete events. Let's take a look at a specific object x labeled y. If the algorithm gives the probability of belonging to the first class - a, then the assumed distribution on the events "class 0", "class 1" is (1–a, a), and the true one is (1–y, y), therefore the Kullback-Leibler discrepancy between them is as in the function below, which exactly coincides with the log loss.
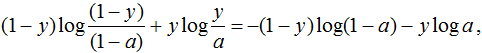
Setting up on log loss
One way to "fit" the algorithm's responses to it is Platt calibration. The idea here is very simple. Let the algorithm generate some estimates of belonging to the 1st class - a. The method was originally developed to calibrate the responses of the support vector machines algorithm (SVM), this algorithm in its simplest implementation separates objects by a hyperplane and simply outputs a class number of 0 or 1, depending on which side of the hyperplane the object is located on. But if we have built a hyperplane, then for any object we can calculate the distance to it (with a minus sign if the object lies in the zero-class half-plane). It is these distances with the sign r that we will convert into probabilities using the following formula:
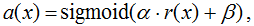
unknown parameters α, β are usually determined by the method of maximum likelihood estimation on calibration set.
Let’s illustrate the application of the method on a real problem, which the author solved recently. The figure below shows the answers (in the form of probabilities) of two algorithms: gradient boosting (lightgbm) and a random forest loss function (random forest).
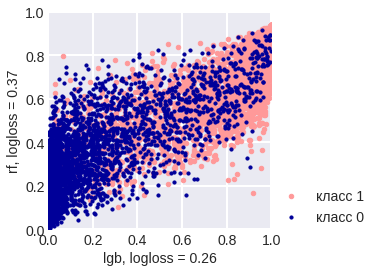
It can be seen that the quality of the forest is much lower and it is rather cautious: it underestimates the probabilities for objects of class 1 and overestimates for objects of class 0. Let us arrange all objects in increasing probability (RF), divide them into k equal parts, and for each part calculate the average of all the responses of the algorithm and average of all correct answers. The result is shown below - the points are shown exactly in these two coordinates.
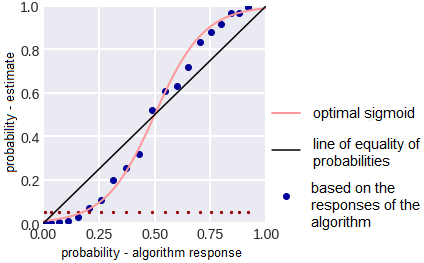
It is easy to see that the points are located on a line similar to a sigmoid - you can estimate the compression-tension parameter in it, it can be seen on the image below. The optimal sigmoid is shown in pink in the figure above. If the responses are subjected to such a sigmoid deformation, then the error of the random forest decreases from 0.37 to 0.33.
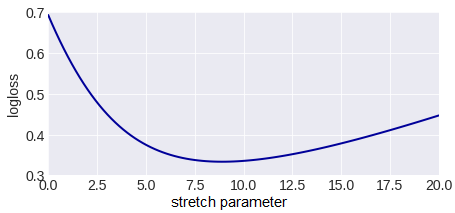
Note that here we have deformed the answers of the random forest (these were probability estimates - and they all lay on the segment [0,1]), but from the probability ratios image it can be seen that the sigmoid is needed for deformation. Practice shows that in 80% of situations, in order to improve the error, it is necessary to deform the answers with the help of the sigmoid (as for me, this is also part of the explanation why exactly such functions are successfully used as activation functions in neural networks).
Another calibration option is isotonic regression.
Multi-class log loss
For the sake of completeness, note that it is generalized to the case of several classes in a natural way:
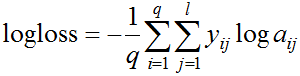
q here is the number of elements in the sample, l is the number of classes, a_ij is the answer (probability) of the algorithm on the i-th object to the question of whether it belongs to the j-th class, y_ij = 1 if the i-th object belongs to the j-th class, otherwise y_ij = 0.
So now you know more about log loss than you did before reading the article. Congratulations. Make some use of it with log loss sklearn or anywhere you please. You might try to learn about negative log loss or using negative log likelihood loss for binary classification.